'My work space/Java'에 해당되는 글 78건
- 2008.08.20 java reverse engineering 간단정리 (자바역공학)
- 2008.08.20 java reverse engineering ( 자바 역공학 )
- 2008.08.20 정규식(Regular Expression) 표현법 및 예제
- 2008.08.20 자바와 MS Access DB연동
- 2008.08.20 Log4J비용계산
- 2008.08.20 싱글톤패턴(Single Pattern)
- 2008.08.20 class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기
- 2008.08.20 Junit 이란?
- 2008.08.20 JUnit 이클립스 사용
- 2008.08.20 JUNIT 사용 가이드라인
간단한 사용법
구글 검색 으로 java reverse engineering ->
http://steike.com/code/java-reverse-engineering/
OS에 맞는 버전 다운 -> Windows version
다운받아서 압축풀면 jad.exe 나오는데 이파일을 클래스가 있는폴더에 붙여넣기하고
cmd창에서 jad *.classe 실행
그러면 classes 파일들이 .jad로 바뀌고 그것은 java파일과 같다
밑에것은 사용법...
용어 정리
java reverse engineering
자바 역공학
decompiler
obfuscator
역공학 방지
jad
to be continue....
------------------------------------------------------------------------------------------------------------------
This is README file for Jad - the fast Java Decompiler.
Jad home page: http://www.kpdus.com/jad.html
Copyright 2001 Pavel Kouznetsov (kpdus@softhome.net).
0. Please read the disclaimer on the Jad home page.
1. Installation.
Unzip jad.zip file into any appropriate directory on your hard drive.
This will create two files:
- an executable file named 'jad.exe' (Windows *)
or 'jad' (*n*x)
- this README file
No other setup is required.
2. How to use Jad
To decompile a single JAVA class file 'example1.class'
type the following:
jad example1.class
This command creates file 'example1.jad' in the current directory.
If such file already exists Jad asks whether you want to overwrite it or not.
Option -o permits overwriting without a confirmation.
You can omit .class extension and/or use wildcards in the names of
input files.
Option -s <ext> allows to change output file extension:
jad -sjava example1.class
This command creates file 'example1.java'. Be careful when using
options -o and -sjava together, because Jad can accidentally overwrite
your own source files.
Jad uses JAVA class name as an output file name. For example, if class
file 'example1.class' contains JAVA class 'test1' then Jad will create
file 'test1.jad' rather than 'example1.jad'. If you want to specify
your own output file name use the output redirection:
jad -p example1.class > myexm1.java
Option -d allows you to specify another directory for output files,
which are created, by default, in the current directory. For example:
jad -o -dtest -sjava *.class
(or jad -o -d test -s java *.class, which has the same effect)
This command decompiles all .class files in the current directory
and places all output files with extension .java into directory 'test'.
If you want to decompile the whole tree of JAVA classes,
use the following command:
jad -o -r -sjava -dsrc tree/**/*.class
This command decompiles all .class files located in all
subdirectories of 'tree' and creates output files in subdirectories
of 'src' according to package names of classes. For example, if file
'tree/a/b/c.class' contains class 'c' from package 'a.b', then
output file will have a name 'src/a/b/c.java'.
Note the use of the "two stars" wildcard ('**') in the previous
command. It is handled by Jad rather than the command shell, so on
UNIX the last argument should be single-quoted:
jad -o -r -sjava -dsrc 'tree/**/*.class'
In a case you want to check the accuracy of the decompilation or just
curious, there is an option -a which tells Jad to annotate the output
with JAVA Virtual Machine bytecodes.
Jad supports the inner and anonymous classes.
When Jad expands wildcards in the input file names,
it automatically skips matching inner classes.
On UNIX Jad skips inner classes if there is more than
one class specified in the command line.
Jad looks for inner classes in the directory of their top-level
container class.
3. List of the command-line options.
Jad accepts the following options:
-a - annotate the output with JVM bytecodes (default: off)
-af - same as -a, but output fully qualified names when annotating
-clear - clear all prefixes, including the default ones (can be abbreviated as -cl)
-b - output redundant braces (e.g., if(a) { b(); }, default: off)
-d <dir> - directory for output files (will be created when necessary)
-dead - try to decompile dead parts of code (if any) (default: off)
-disass - disassemble method bytecodes (no JAVA source generated)
-f - output fully qualified names for classes/fields/methods (default: off)
-ff - output class fields before methods (default: after methods)
-i - output default initializers for all non-final fields
-l<num> - split strings into pieces of maximum <num> chars (default: off)
-lnc - annotate the output with line numbers (default: off)
-lradix<num> - display long integers using the specified radix (8, 10 or 16)
-nl - split strings on newline character (default: off)
-nocast - don't generate auxiliary casts
-nocode - don't generate the source code for methods
-noconv - don't convert Java identifiers (default: convert)
-noctor - suppress the empty constructors
-nodos - do not check for class files written in DOS mode (CR before NL, default: check)
-nofd - don't disambiguate fields with the same names by adding signatures to their names (default: do)
-noinner - turn off the support of inner classes (default: on)
-nolvt - ignore Local Variable Table information
-nonlb - don't output a newline before opening brace (default: do)
-o - overwrite output files without confirmation (default: off)
-p - send decompiled code to STDOUT (e.g., for piping)
-pi<num> - pack imports into one line after <num> imports (default: 3)
-pv<num> - pack fields with identical types into one line (default: off)
-pa <pfx>- prefix for all packages in generated source files
-pc <pfx>- prefix for classes with numerical names (default: _cls)
-pf <pfx>- prefix for fields with numerical names (default: _fld)
-pe <pfx>- prefix for unused exception names (default: _ex)
-pl <pfx>- prefix for locals with numerical names (default: _lcl)
-pm <pfx>- prefix for methods with numerical names (default: _mth)
-pp <pfx>- prefix for method parms with numerical names (default: _prm)
-r - restore package directory structrure
-radix<num> - display integers using the specified radix (8, 10 or 16)
-s <ext> - output file extension (by default '.jad')
-safe - generate additional casts to disambiguate methods/fields (default: off)
-space - output space between keyword (if/for/while/etc) and expression (default: off)
-stat - display the total number of processed classes/methods/fields
-t - use tabs instead of spaces for indentation
-t<num> - use <num> spaces for indentation (default: 4)
-v - display method names being decompiled
-8 - convert UNICODE strings into 8-bit strings
using the current ANSI code page (Win32 only)
-& - redirect STDERR to STDOUT (Win32 only)
All single-word options have three formats:
-o - 'reverses' value of an option
-o+ - set value to 'true' or 'on'
-o- - set value to 'false' or 'off'
You can specify the options you want to be set by default in the environment variable
JAD_OPTIONS. For example:
JAD_OPTIONS=-ff+ -nonlb+ -t+ -space+
'My work space > Java' 카테고리의 다른 글
| java reverse engineering ( 자바 역공학 ) (0) | 2008.08.20 |
|---|---|
| 정규식(Regular Expression) 표현법 및 예제 (0) | 2008.08.20 |
| 자바와 MS Access DB연동 (0) | 2008.08.20 |
| Log4J비용계산 (0) | 2008.08.20 |
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
개발이 완료되어 유지보수가 이루어지고 있는 소프트웨어 시스템의 구성요소를 알아 내고,
구성요소들 간의 관계를 식별하고, 대상(object) 시스템을 분석하는 과정이다.
즉, 소프트웨어 생명주기의 마지막 단계에서 얻어지는 프로그램이나 문서 등을 이용하여
생명주기 초기 단계의 생성물에 해당하는 정보나 문서들을 만들어 내는 일로서,
설계부터 순차적으로 이루어지는 순공학에 상대되는 개념으로 역공학이라 한다.
처음에는 하드웨어 분야에서 완제품으로부터 제품의 설계사양을 추출하려는 목적에서 출발했으며,
리코프(M.G.Rekoff)는 이를 "복잡한 하드웨어 시스템의 견본을 분석하여 일련의 설계명세를 개발하는 과정"이라고 정의하였다.
그런데 컴퓨터를 기반으로 하는 소프트웨어 공학이 널리 소개되면서 기존의 정보시스템을 소프트웨어 공학의 방법으로
재정의하여 시스템의 품질을 향상하고 유지보수와 관련된 업무를 개선하려는 요구가 생겼고,
이를 충족시키는 방법으로 역공학이 이용되기 시작했다.
이렇게 역공학은 시스템을 이해하여 적절히 변경하는 소프트웨어 유지보수 과정의 일부이다.
대상 시스템을 변경시키거나 새로운 시스템으로 개선하는 것이 아니라 기존 시스템을 분석하는 작업이라 할 수 있다.
그렇다고 소프트웨어 유지보수 단계에만 한정되는 것은 아니고,
직간접적으로 소프트웨어 개발을 지원하기도 한다.
기존 시스템에 역공학을 적용하여 설계구조를 뽑아 내고,
이를 이용해 시스템 분석과 설계를 향상시키는 일이 그런 예이다.
또한 역공학된 설계 정보는 새로운 시스템 설계의 출발점이 되기도 하며,
수정되어 새로운 시스템을 탄생시키기도 한다.
그러나 역공학은 다분히 한시적인 기술로 전락할 가능성이 있다.
순공학의 자동화기술 분야가 발전하면 역공학의 필요성은 상대적으로 줄어들게 된다.
또한 현재 개발되어 있는 역공학의 도구와 기술이 많은 부분 통합되어 있지 않아
실제로 도입하여 적용하는데 장애물이 되고 있다.
■ 리버스엔지니어링이란?
- 하드웨어 또는 소프트웨어에 대한 분해,분석을 통해 당해 제품에
구현된 아이디어(원리, 기술, 방법, 기능, 알고리즘, 노하우등을 포함)를 추출해 내는 일련의 행위
- ‘역공학’, ‘역분석’ 등으로 불리기도 함
■ 리버스엔지니어링 허용의 필요성
- 패키지 솔루션의 경우 실행모듈형태로 제공받는게 일반적인데
소스코드의 변경이 필요해질경우 개작, 번역 등을 수반하게되어 저작권자의
허락 없이 이루어지게 되므로 저작권 침해의 문제가 발생
이러한 경우까지 저작권자를 과도하게 보호한다면 권리자․이용자간의 이익 형평과 공익을
추구하는 저작권 제도의 취지에 반하게 되므로 일정한 경우에는 리버스엔지니어링을 허용하는 것이 필요
리버스 엔지니어링이란?
리버스 엔지니어링이란 완성된 제품을 상세하게 분석하여 제품의 기본적인 설계 개념과 적용 기술들을 파악하고
재현하는 것입니다. 설계 개념→개발 작업→제품화의 통상적인 추진 과정을 거꾸로 수행하는 학문으로 역공학이라고도 합니다.
보통 소프트웨어 제품은 판매시 소스는 제공하지 않으나 각종 도구를 활용하여 컴파일된 실행 파일과 동작 상태를
정밀 분석하면 그 프로그램의 내부 동작과 설계 개념을 어느 정도는 추적할 수 있습니다.
이러한 정보를 이용하면 크랙, 즉 실행 파일을 수정하거나 프로그램의 동작을 변경하는 것이 가능하고,
또 유사한 동작의 복제 프로그램이나 보다 기능이 향상된 프로그램도 개발해 낼 수가 있게 됩니다.
소프트웨어에 대한 역공학 자체는 위법 행위가 아니지만,
대부분의 제품이 이의 금지를 명문화 하고 있어 이러한 수법으로 개발한 제품은 지적 재산권을 침해할 위험성이 있습니다.
리버스 엔지니어링의 기술
- 언패킹(UNPACKING)
일반적인 SW들은 리버스엔지니어링을 막기 위해서 암호화를 하거나 압축을 하여 소스코드를 볼 수 없도록 하고 있습니다.
이러한 과정을 패킹(PACKING)이라고 합니다.
소스코드를 보기 위해서는 이렇게 패킹된 코드를 풀어야 하는데 이러한 과정을 언패킹(UNPACKING)이라고 합니다.
- 분석단계
언패킹된 파일은 리버스엔지니어링을 위해 기본적으로 정적 분석(static analysis)과
동적 분석(dynamic analysis)단계를 거치게 됩니다.
리버스 엔지니어링의 종류
통상적으로 컴파일된 바이너리(EXE, DLL, SYS 등)를 디스어셈블러라는 도구를 이용하여
어셈블리 코드를 출력한 후 그것을 C언어 소스형태로 다시 옮겨 적고 적당한 수정을 통해
리버스하고 있는 파일과 동일한 동작을 하는 프로그램을 만드는 것이 있습니다.
모든 어셈블리 코드를 소스 형태로 옮기지 않고 그냥 동작 방식만을 알아낸다거나
일정 부분만 수정하는 것들도 리버스 엔지니어링이라고 할 수 있습니다.
예를 들면 바이러스를 분석하는 일은 모든 코드를 알아낼 필요가 없기 때문에 동작 방식만 알아내면 됩니다.
그리고 크랙처럼 일정 부분만 수정하여 사용제한을 푸는 것 등도 이에 해당됩니다.
실행파일을 디스어셈블 하지 않고도 그 실행파일이 만들어내는 데이터 파일이나 패킷등을 분석하여
똑같이 재구현하는 것도 리버스 엔지니어링입니다. 예를 들면 오래전 PC 게임에서 많이 하던일인데,
HEX 에디터 등으로 세이브 파일을 분석하여 에디트를 만들거나 게임자체를 조작하는 것이 있고,
당나귀와 호환되는 이뮬 같은 프로그램은 당나귀 프로토콜의 패킷을 분석하여 동일한 동작을 하도록 만들어낸 것입니다.
리버스 엔지니어링에서 가장 많이 사용되는 방식은 첫번째로 이야기 했던
바이너리를 디스어셈블 하여 코드를 얻어내는 것입니다.
이것을 하기 위해서는 먼저 인텔 어셈블리를 배워야 하고, 물론 C언어도 알아야 됩니다.
그런데 여기서 컴파일된 바이너리가 VC나 gcc등으로 컴파일한 것이 대부분이지만
비주얼 베이직으로 컴파일 한 것도 있고 델파이(파스칼)로 컴파일 한 것도 있을 것입니다.
이 바이너리들은 모두 CPU에서 직접 실행되는 것들이기 때문에 디스어셈블 해보면 모두 똑같은 방식으로 되어 있습니다.
그래서 VC, VB, 델파이(파스칼)등으로 컴파일 된 것도 디스어셈블 한 뒤 C 소스 코드로 옮길 수 있습니다.
물론 리버스 하는 사람이 VB나 파스칼로 옮겨 적을 수도 있을 것입니다.
하지만 C언어로 하는 것이 가장 간편합니다.
대부분 리버스해서 얻어내는 것들은 프로그램의 로직(알고리즘)이기 때문에 어느 언어로 표현하든 결과는 똑같기 때문입니다.
자바나 닷넷으로 컴파일 된 바이너리는 CPU에서 직접 실행되지 않고 자바 가상머신이나 닷넷 프레임워크를 통해서 실행됩니다.
그래서 자바로 컴파일된 바이너리를 열어보면 자바 바이트코드 문법으로 되어 있고
닷넷으로 컴파일 된 것은 MSIL이라는 문법으로 되어 있습니다.
이런 것을은 인텔 어셈블리와 문법이나 명령어가 다르므로 따로 자바 바이트코드나 MSIL을 공부해서 리버스 하면 되겠습니다.
윈도우용 바이너리를 리버스 한다고 하면 윈도우 API를 알아야 하고 기타 리눅스나 BSD라면 해당 OS의 API를 알아야 합니다.
그리고 당연히 인텔 어셈블리를 알고 있어야 하고, 인텔 CPU가 돌아가는 방식을 알아야 합니다.
프로그램은 단순히 로직만으로 이루어져 있지 않고 시스템의 API를 호출하여 여러가지 동작을 하기 때문에
각 API의 사용방법과 동작결과를 알고 있어야 어셈블리 코드에서
C소스 코드로 옮기고 다시 소스를 재구현할 수 있기 때문입니다.
어플리케이션을 리버스하는 경우 윈도우 커널에 대한 지식이 없어도
리버스가 가능하지만 커널 레벨로 동작하는 드라이버나 기타 서비스는 윈도우 커널에 대한 지식이 필요합니다.
어셈블리에서 C소스 코드로 옮기는 작업은 한마디로 단순 반복작업입니다.
디스어셈블된 코드에서 call은 함수이고 각종 점프 명령어들은 if, for, while, switch, goto 등의 C언어 제어문입니다.
mov 명령어는 변수에 값을 대입한다거나 하는 것이고 push, pop 명령은 함수를 호출하면서
인자값을 넘겨줄 때 사용합니다. 이 어셈블리 명령의 조합을 읽어 C코드로 구현을 하면 됩니다.
각종 도구들
리버스 엔지니어링에서는 디스어셈블러라는 도구가 매우 필수적입니다.
자주 쓰이는 것들로는 리버스계에서 아주 유명한 소프트아이스(SoftICE, 이하 소아)라는 프로그램이 있습니다.
소아의 특징으로는 윈도우가 돌고 있는 상태에서 Ctrl+D를 누르면 윈도우가 멈추고 소아 창이 떠서 현재 실행되고 있는
어셈블리 코드를 보여줍니다. 정말 강력하고 편리한 기능입니다.
이 기능이 소아를 쓰는 이유이기도 합니다.
물론 그냥 바이너리를 열어서 디스어셈블도 가능하며 요즘은 비주얼 소프트아이스라고 나와서
원격 디버깅도 가능합니다. 단 비쌉니다.
WinDBG(Windows Debugger)는 MS에서 배포하는 무료 디버거인데 윈도우 내부를 분석하는데 매우 유용한 도구입니다.
심볼 서버에서 심볼 파일을 받아와서 윈도우 내부 DLL들의 함수이름과 구조체 등을 볼 수 있습니다.
물론 이것도 그냥 바이너리를 열어 디스어셈블이 가능합니다.
OllyDBG, 아주 편리한 도구입니다. 리버스하기에는 딱 알맞은 도구가 아닌가 싶습니다.
디스어셈블 뿐만 아니라 이 디버거가 어셈블리 코드를 분석하여 사용자에게 많은
정보(함수 이름, 인자값 이름, 서브루틴끼리 묶어주는 기능, 점프명령의 도착점 표시 기능 등)를 제공해 줍니다.
W32dasm는 OllyDBG처럼 인터렉티브 하지는 않지만 상당히 쓸만한 도구입니다.
기타 IDA나 PE Browse등의 프로그램이 있는데 사용자 취향에 따라 골라 쓰면 되겠습니다.
거의 모든 디버거에서 레지스터, 스택, 메모리 상태 등을 표시해 주고 있으므로 코드 분석에 많은 도움이 됩니다.
마지막으로 주의할 점은 같은 바이너리를 디스어셈블한다고 하더라도 디스어셈블러마다 분석해 내는 코드가
조금씩 다른 경우가 있습니다. 그래서 한가지 디버거만 쓰다 보면 엉뚱한 코드를 보기 쉽습니다.
여러가지 디버거를 돌려 가면서 코드를 분석하는 것도 좋은 방법입니다.
'My work space > Java' 카테고리의 다른 글
| java reverse engineering 간단정리 (자바역공학) (0) | 2008.08.20 |
|---|---|
| 정규식(Regular Expression) 표현법 및 예제 (0) | 2008.08.20 |
| 자바와 MS Access DB연동 (0) | 2008.08.20 |
| Log4J비용계산 (0) | 2008.08.20 |
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
* \ (backslash) - 정규식에 사용되는 특수문자, 예를 들어 * 나 \ 등을 매치할때 사용한다. 즉, * 를 매치하려면 \* 라고 써줘야한다.
* \t - 탭 문자와 매치된다.
* \n - 새줄문자와 매치된다.
* \r - 리턴문자와 매치된다.
* \f - form feed문자와 매치된다.
* [^a-zA-Z] - 위와 반대다. 즉 a에서 z까지, A에서 Z까지 사이에 없으면 매치된다.
* \w - 알파벳과 _ (영어단어에 쓰이는 문자)
* \W - 알파벳과 _이 아닌 것
* \s - 빈 공간
* \S - 빈 공간이 아닌 것
* \d - 숫자
* \D - 숫자가 아닌 것
* $ - 줄의 맨끝과 매치된다.
* \b - 단어와 단어의 경계와 매치된다.
* (A) - A와 매치한것을 나중에 다시 사용할 때 쓴다.
* \2 - 두번째 괄호에 매치된 부분
* 세번째는 $3, 네번째는 $4 등으로 사용하면 됨
* A+ - A를 한번, 아니면 그 이상 매치한다.
* A? - A를 0번, 아니면 한번만 매치한다.
* A{n} - A를 정확히 n번 매치한다.
* A{n,} - A를 n번 이상 매치한다.
* A{n,m} - A를 최소한 n번, 하지만 m번 이하로 매치한다.
2) 정규식 예제
'My work space > Java' 카테고리의 다른 글
| java reverse engineering 간단정리 (자바역공학) (0) | 2008.08.20 |
|---|---|
| java reverse engineering ( 자바 역공학 ) (0) | 2008.08.20 |
| 자바와 MS Access DB연동 (0) | 2008.08.20 |
| Log4J비용계산 (0) | 2008.08.20 |
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
우선 JDBC Driver의 종류에 대해 소개한다.
JDBC Driver종류
| 1 | JDBC/ODBC Bridge |
|
이것은 JDK1.2 부터 포팅되어 있으므로 추가로 설치할 필요는 없다. JDBC 함수호출을 ODBC 함수호출로 전환하기 때문에 만약 예전에 사용하던 환경이 ODBC 를 이용해 구축되어 있다면 굳이 다른 드라이버를 사용하지 않고서도 시스템을 확장해 나갈수가 있다. 하지만 ODBC 계층을 경유하기 때문에 데이타복사시 오버헤드를 야기하고, 클라이언트에는 반드시 ODBC DRIVER 가 설치돼 있어야 한다. 자바 하위버전에서는 추가로 JDBC DRIVER 까지 설치돼 있어야 함은 물론이다. 또한 ODBC 와 DB 간에 소켓을 사용하기 때문에 방화벽을 통과하지 못하기 때문에 익스트라넷 환경에서 사용할 수가 없다. 또한 ODBC 접속부분에서 100% 자바코드를 사용하지 않기 때문에 애플릿으로도 연결할 수가 없다. 굳이 사용하고자 한다면 ODBC 환경설정을 따르는 MS-SQL SERVER 에 적당하다 하겠다. |
| 2 | Native-API,Partly-Java Driver |
|
사용환경은 JDBC/ODBC 와 유사하다. 이것은 JDBC 호출을 특정데이타베이스에서 사용하는 API 로 전환한다. 이 드라이버 역시 C/C++ 코드로 네이티브 메소드를 사용하기 때문에 클라이언트에 해당 DB 의 라이브러리가 설치돼 있어야 한다. 자체 DB DLL 를 사용하기 때문에 JDBC/ODBC 보다는 속도 향상이 있다. 하지만 여전히 오버헤드 문제가 제기되고 방화벽을 통과하지 못하기 때문에 익스트라넷 환경에서는 사용할 수가 없다.
|
| 3 | Net-Protocol, All-Java Driver |
|
이것은 3-tier 모델이다. 클라이언트 측에는 드라이버 클래스와 API 가 위치하고, 실제 기능은 JDBC 미들웨어에서 구현한다. 클라이언트는 자바로 구현되기 때문에 애플릿을 통해 구현할 수 있으나 애플릿의 특성상 JDBC 미들웨어가 웹서버와 같은 호스트에 위치하여야 한다. 3-tier 환경이 주는 이점(다중 DB 접속, 질의 캐싱, 로드밸런싱,보안기능)을 이용할 수 있으며 대규머 클라이언트/서버 환경에 적합한 모델이다. 흔히 JDBC 미들웨어와의 표준프로토콜로서 CORBA 의 IIOP 나 HTTP 를 이용한다. 서버는 각 클라이언트의 요구는 DBMS 프로토콜로 바꿔 쿼리를 전달하며 반환된 결과값을 다시 클라이언트에 전달한다. 주로 통합 구성된 단일 드라이버 형태로 제공하며 멀티 DBMS 환경에 적합하다.
|
| 4 | Native-Protocol, All-Java Driver |
|
JDBC 호출을 바로 DBMS 가 사용하는 프로토콜로 전환해 DBMS 와 직접 연결해 준다. DBMS 의 모든 기능을 자바로 직접 구현하였기 때문에 ODBC 나 DB 라이브러리가 별도로 필요가 없으며 모든 드라이버가 자바로 구현됐기 때문에 애플릿으로도 다운로드돼 실행될 수가 있다. 가령,
|
다음 예제는 JDBC/ODBC Bridge Driver를 이용한 JAVA Source이다.
우선 MS Access DB로 만든 테이블을 를 제어판에서 등록한다.
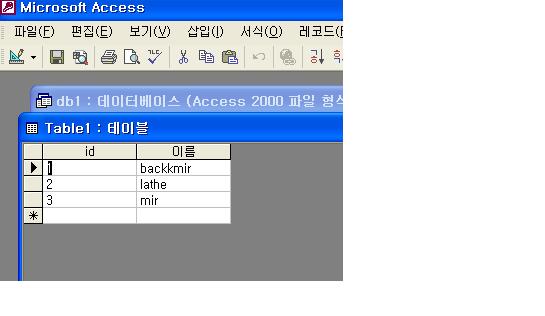
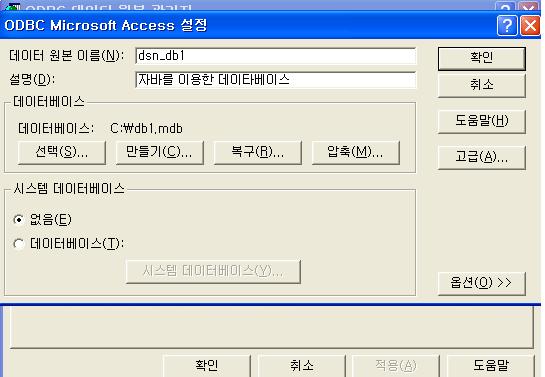
이렇게 DB가 등록이 완료되면 코딩시작...
import java.sql.*;
import java.util.*;
import javax.swing.*;
public class AccessTest
{
public ResultSet resultSet; //질의문의 결과를 처리하는 클래스
public ResultSetMetaData metaData; //메타데이터
public int numberOfRows; //테이블의 행
public Connection db=null;
public Statement stmt=null;
String queryState="";
String sql = "SELECT * FROM Table1"; //테이블 명
static final String JDBC_ODBC_DRIVER="sun.jdbc.odbc.JdbcOdbcDriver";
static final String url="jdbc:odbc:dsn_db1"; //dsn_db1은 DB이름
public AccessTest()
{
try
{
/*JDBC - ODBC Bridge Driver Setting*/
Class.forName(JDBC_ODBC_DRIVER);
db=DriverManager.getConnection(url,"","");
//SQL문 작성을 위한 Statement를 준비
stmt=db.createStatement();
resultSet = stmt.executeQuery(sql); //query를 실행
//Query 실행값을 저장할 버퍼*/
StringBuffer results = new StringBuffer();
ResultSetMetaData metaData = resultSet.getMetaData(); //MetaData를 얻는다.
int numberOfColumns = metaData.getColumnCount(); //테이블의 컬럼개수를 가져온다.
while(resultSet.next())
{
for(int i=1;i<=numberOfColumns;i++)
results.append(resultSet.getObject(i)+"\t");
results.append("\n");
}
System.out.println(results);
} //try의 끝
catch(SQLException sqlException){
JOptionPane.showMessageDialog( null,sqlException.getMessage(), "DataBase ERROR",
JOptionPane.ERROR_MESSAGE );
System.exit(1);//비정상적으로 종료시킨다.
}
catch(ClassNotFoundException classNotFound){
JOptionPane.showMessageDialog(null,classNotFound.getMessage(),
"Driver Not Found",JOptionPane.ERROR_MESSAGE);
System.exit(1);
}
finally{
/*연결된 데이타베이스를 닫는다.*/
try{
stmt.close();
db.close();
}
catch(SQLException sqlException){
JOptionPane.showMessageDialog(null,
sqlException.getMessage(), "DataBase Error",
JOptionPane.ERROR_MESSAGE);
System.exit(1);
}
}
}
/*main Function*/
public static void main(String[] args)
{
AccessTest test = new AccessTest();
}
}
-실행결과-
1 backkmir
2 lathe
3 mir
Press any key to continue...
[출처] 자바와 MS Access DB연동|작성자 미르
'My work space > Java' 카테고리의 다른 글
| java reverse engineering ( 자바 역공학 ) (0) | 2008.08.20 |
|---|---|
| 정규식(Regular Expression) 표현법 및 예제 (0) | 2008.08.20 |
| Log4J비용계산 (0) | 2008.08.20 |
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
| class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기 (0) | 2008.08.20 |
기존의 System.out.println() 으로 로깅 할 때 발생하는 문제의 대안으로 Log4J를 요즘 많이 사용한다.
Log4J를 사용하면 OutputStream시 발생하는 자원독점 문제 해결, logging 레벨 설정을 코드와 분리, 로깅 output target 설정 변경 등 다양한 잇점을 얻을 수 있다.
그러나 Log4J가 실행될 때 발행하는 비용을 계산해 보면 Log4J를 사용할 때 주의가 필요하다.
무작정 사용하는 것은 WAS 전체에 심각한 문제를 발생 시킬 수 있다.
모 사이트에서 JVM의 GC가 자주 발생하는 문제가 발생하여 시스템 전체에 심각한 문제가 발생한 사례가 있었다. 물론 Log4J가 문제의 핵심은 아니었지만 어느 정도 영향은 미쳤다고 생각된다.
지금 다룰 내용은 "Log4J The Complete Manual" 23 페이지에 나온 내용을 참조하였다.
이 내용을 메뉴얼을 읽을 때는 심각하게 받아 들이지 않았지만 실제 사례를 접하니 간과할 수만은 없는 문제인 듯 싶다.
문제 코드 분석
문제가 발생한 사이트는 Struts를 기반으로 하는 프레임웍 구조를 갖고 있었다.
Session 정보를 추출하기 위하여 다음과 같은 코드가 공통 코드 레벨에서 수행되고 있었다.
while ( i.hasNext() ) {
Map.Entry e = (Map.Entry) i.next();
logger.debug("TABLE KEY : " + e.getKey() );
logger.debug("SESSION ID : " + ((HttpSession) e.getValue()).getId());
}
특정 상황에서 이 코드는 246번의 반복을 수행하였고, 두 개의 debug()이 실행하면서 각각 8메가의 임시 객체를 생성하였다. 해당 while문이 수행되면서 16메가의 임시 객체를 생성하였다.
물론 문제의 while문이 구동할 때 Log4J는 DEBUG 모드로 운영중인 상태였다.
이 코드로 발생하는 문제는 Log4J를 DEBUG 모드로 운영 중이기 때문에 발생한 것이고 WARNING이나 ERROR 모드로 운영하면 문제가 발생하지 않는다고 생각할 수도 있다. 그러나 Log4J가 실행되는 비용을 계산해 보면 이러한 문제는 Log4J의 운영 모드를 변경해도 동일하게 발생한다는 것을 알수 있다.(물론 일정 부분 감소는 할 것이다.)
1. Log4J 로깅 메소드 비용 계산
예제 코드
logger.debug("Entry number: "+i+" is "+String.valueOf(entry[i]));
예제 코드와 같은 코드가 있다고 할 때 다음과 같은 순서로 실행된다.
- logging 문자열 생성
- String 문자열 1개 생성: "Entry number: "
- String 문자열 1개 생성 총 2개: "Entry number: " + i
- String 문자열 1개 신규 생성, + 결합 1개 생성, 총 4개: 신규 생성: " is ", 결합 문자열: "Entry number: " + +i+" is "
- String 문자열 1개 신규 생성, + 결합 1개 생성, 총 6개: 신규생성: String.valueOf(entry[i]), 결합문자열: "Entry number: "+i+" is "+String.valueOf(entry[i])
- String 문자열 1개 생성: "Entry number: "
- logger의 logging 레벨 체크
- 현재 등록된 로거의 로깅 레벨을 체크
- 현재 logger의 로깅 레벨이 DEBUG이면 다음단계 진행
- 현재 logger의 로깅 레벨이 INFO 이상이면 정지
- 현재 등록된 로거의 로깅 레벨을 체크
- logger의 appender에 등록된 output에 출력
- layout 적용
- 출력
- layout 적용
위와 같은 순서로 실행된다.
2. Log4j 운영 모드에 따른 비용 계산
- Debug 모드일 때
- 1번 로깅 문자열 생성 = 6개의 스트링 객체 생성, 1개만 사용, 5개의 스트링 객체는 GC 대상
- 2번 logger의 레벨 체크 실행
- 3번 로깅 실행 - layout 적용 후 output에 로깅 적용
- 1번 로깅 문자열 생성 = 6개의 스트링 객체 생성, 1개만 사용, 5개의 스트링 객체는 GC 대상
- non-Debug 모드일 때
- 1번 로깅 문자열 생성 = 6개의 스트링 객체 생성, 1개만 사용, 5개의 스트링 객체는 GC 대상
- 2번 logger의 레벨 체크 실행
- 3번 실행 없이 종료
- 1번 로깅 문자열 생성 = 6개의 스트링 객체 생성, 1개만 사용, 5개의 스트링 객체는 GC 대상
로그의 모드에 따라서 Log4J에서 생략되는 부분은 3번에 국한된다. 즉 로깅 문자열 생성이나 로그 레벨 체크의 비용은 발생한다. 여기서 로그레벨 체크는 전체 로깅 비용의 1%이하이고 극히 적은 비용을 발생하기 때문에 2번은 큰 문제가 되지 않을 수 있다. 그러나 1번의 발생 비용은 경우에 따라서 매우 심각해 질 수도 있다.
1번의 로깅 문자열은 스트링을 "+"하는 방식이기 때문에
수백번의 loop안에서 발생하거나 로깅 로직이 빈번하게 발생하는 조건에서는 temporary object를 양산하는 로직이 될 가능성이 크다.
위의 Log4j 운영 모드에 따른 실행 순서에서 알수 있듯이 이것은 로깅 모드를 변경한다고 해서 발생하지 않는 부분은 아니다.
3. 문제 해결 코드
if(logger.isDebugEnabled() {
logger.debug("Entry number: "+i+" is "+String.valueOf(entry[i]));
}
위와 같은 코드의 사용이 바람직 하다. 이러한 코드는 Log4J의 예제에서 나오는 isDebugEnabled() 메소드를 이용하는 방법이다. 실제 프로젝트에서 보변 isDebugEnabled 메소드의 사용을 간과 하는 경우가 많다.
이 코드를 사용하면 로깅 문자열을 생성하기 전에 로깅 레벨을 체크하는 isDebugEnabled 메소드를 실행하여 로깅을 실행할 것인가를 미리 체크하게 된다. 기본적인 코드이지만 이러한 코드를 사용하는 것은 매우 중요하다.
4. 문제 해결 코드의 side-effect
이 코드는 DEBUG 모드일대 부가적인 문제를 발생 시킨다.
if(logger.isDebugEnabled() {
logger.debug("Entry number: "+i+" is "+String.valueOf(entry[i]));
}
이 코드는 DEBUG 모드일 때 LOGGER의 실행 레벨 체크를 두번한다는 단점을 갖는다.
isDubugEnabled 메소드에서 한번 체크하고 debug 메소드에서 다시 체크한다. debug 모드에서 로깅 레벨 체크후 degub 상태이면 로깅을 한다.
이러한 실행 과정은 단일 로깅일 때는 문제가 되지 않지만(로깅 전체에서 체크의 실행 비용은 1% 이하이다.) debug 메소드가 loop 문 안에 있거나, 하나의 메소드에서 debug 메소드가 여러번 호출될 때는 문제가 될수 있다. 1%이하라도 반복적으로 실행된다면 문제가 될 것이다.
public void foo(Object[] a) {
for(int i = 0; i < a.length; i++) {
if(logger.isDebugEnabled()){
logger.debug("Original value of entry number: "+i+" is "+a[i]);
}
a[i] = someTransformation(a[i]);
if(logger.isDebugEnabled()){
logger.debug("After transformation the value is "+a[i]);
}
}
위 와 같은 메소드가 있을 경우에는 반복문속에서 두번의 debug 메소드가 실행된다.
Debug 모드 운영 중이라고 가정할 때
반복문 속에서
1. 로그레벨 체크
2. 로그레벨 체크 후 로깅
3. 로그레벨 체크
4. 로그레벨 체크 후 로깅
의 순서로 실행된다. 반복문 자체도 문제지만 반복적인 로깅 체크 역시 문제이다. 이러한 코드는 다음과 같이 변경하는 것이 바람직하다.
public void foo(Object[] a) {
boolean isLogging = logger.isDebugEnabled();
for(int i = 0; i < a.length; i++) {
if(isLogging ){
logger.debug("Original value of entry number: "+i+" is "+a[i]);
}
a[i] = someTransformation(a[i]);
if(isLogging ){
logger.debug("After transformation the value is "+a[i]);
}
}
}
작은 결론 debug 메소드 사용시 주의 사항
지금은 debug 메소드에 대해서 알아 보았다. debug 메소드를 사용할 경우 다음과 같은 두가지 사항에 주의해야 할 것이다.
1. isDebugEnabled 메소드를 사용하여 사전에 로그레벨 체크: 불필요한 로깅 문자열 생성 비용 절감
2. 반복문에서는 isDebugEnabled 메소드를 반복문 외부에서 실행하여 결과 저장 및 반복문 안에서 재사용: 불필요한 로깅 레벨 중복 체크의 비용 절감
또다른 숙제...
Log4J를 사용함으로써 예전에 로깅 문제의 만은 부분은 해결되고 있지만 Log4J에 대한 올바른 사용에 주의를 기울일 필요가 있다. 지금은 debug 메소드만을 다루었지만 debug 외의 info(), warning(), error(), fatal() 메소드 역시 동일한 문제를 내포하고 있다.
이러한 고민에 앞서 로깅 관련 코드를 작성할 때 로깅 문자열 생성에 대한 각별한 주의가 필요한 것 같다.
'My work space > Java' 카테고리의 다른 글
| 정규식(Regular Expression) 표현법 및 예제 (0) | 2008.08.20 |
|---|---|
| 자바와 MS Access DB연동 (0) | 2008.08.20 |
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
| class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기 (0) | 2008.08.20 |
| Junit 이란? (0) | 2008.08.20 |
싱글톤(Singleton) Pattern 이란?
객체지향형언어(OOP)에 대해 조금이라도 파고든 사람이라면 싱글톤 패턴이라는
말을 들어봤을 것이다. 못들어봤다면 이제부터 들었다고 해라. 싱글톤이란 생성하고자
하는 인스턴스의 수를 오직 하나로 제한하는 디자인 패턴이다.
그렇다면 왜 싱글톤 패턴을 사용해야하는 것일까? 라는 질문에 대게 답하는 것이
여러개의 인스턴스를 생성하게 되면 가끔 프로그래머도 당혹스럽게 되는 서로의
인스턴스에 간섭을 하는 경우가 있다. 정말 재수 없는 일이 아닐 수가 없다.
public class Singleton
{
private static Singleton singleton = new Singleton();
protected Singleton()
{
System.out.println("Maked Singleton");
}
public static Singleton getInstance()
{
return singleton;
}
}
싱글톤의 기본형이다. singleton 멤버변수는 static 이어야한다는 것과 Singleton 클래스의
생성자는 private / protected 이어야한다는 것을 꼭 유념해야한다. private 일 경우는 결코
new 를 이용하여 인스턴스의 중복 생성을 방지하는 셈이기도 하나 상속이 되지 않는다는
단점이 있어 protected로 대게 선언한다.
뭐~ 싱글톤 패턴이 만들어졌나 아닌가 확인할 것이라면 Test 클래스를 만들어보자.
public class Test
{
public static void main(String [] args)
{
System.out.println("Singleton pattern");
Singleton sg1=Singleton.getInstance();
Singleton sg2=Singleton.getInstance();
if( sg1 == sg2 )
{
System.out.println("Equal");
}
else
{
System.out.println("Not Equal");
}
}
}
여기서 보면 Singleton 의 인스턴스를 생성하기 위해 getInstance() 메소드를 이용한다.
왜 그럴까? Singleton 클래스의 private static Singleton singleton = new Singleton();
부분을 유심히 바라보기 바란다. 이 singleton은 static으로 선언된다. 즉 하나의 인스턴스
singleton 만 생성하는 셈이다. 아마 결과도 Equal로 출력될 것이다.
'My work space > Java' 카테고리의 다른 글
| 자바와 MS Access DB연동 (0) | 2008.08.20 |
|---|---|
| Log4J비용계산 (0) | 2008.08.20 |
| class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기 (0) | 2008.08.20 |
| Junit 이란? (0) | 2008.08.20 |
| JUnit 이클립스 사용 (0) | 2008.08.20 |
class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기
보통 class 안에서 선언된 callback함수는 접근이 안된다.
class T
{
public:
void CALLBACK test();
}
보통 이렇게 되어 있다고 하면 접근을 하기 위해서 static을 붙여주기도 한다.
class T
{
public:
static void CALLBACK test();
}
하지만... callback함수 안에서 다시 class 안에 있는 멈버 변수에 접근을 하지 못하게 된다.
내가 해결한 방법으로는
class 안에서 class 변수를 static으로 선언을 해주어서는 this 포인터로 접근하였다.
class T
{
private:
static T* m_pInstance;
public:
void CALLBACK test();
}
생성자에서는
T::T(void)
{
m_pInstance = this;
}
그리고 마지막으로 전역변수로
T* T::m_pInstance = NULL;
이렇게 하면 callback함수 안에서 class 암에 있는 멤버 변수에 접근이 가능하게 된다.
void CALLBACK T::test()
{
m_pInstance->변수이름;
m_pInstance->함수;
}
'My work space > Java' 카테고리의 다른 글
| Log4J비용계산 (0) | 2008.08.20 |
|---|---|
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
| Junit 이란? (0) | 2008.08.20 |
| JUnit 이클립스 사용 (0) | 2008.08.20 |
| JUNIT 사용 가이드라인 (0) | 2008.08.20 |
xp: 주된작업이 코딩부분에 초점을 두고 있는 경량 개발 방법론
xp의 중심적인 중요사항 : 의사소통(communication), 단순성(simplicity), 피드백(feedback),자신감(courage)에 기초를 한다.
의사소통은 짝프로그래밍, 작업견해논의, 반복되는 계획을 수월하게 수용할수 있는가에 대한 중요요소,
단순성은 같은 내용을 과도하게 작성하지 않고 기본에 충실하여 간결한 구조를 처음부터 끝까지 유지하는데에 있다.
피드백은 매우중요하며 코드테스팅, 고객의 요구 사항, 부분적인 반복작업및 여러차례의 결과물인도, 짝프로그래밍/지속적인 코드 검토등의
과정에 의해 이루어진다.
자신감은 문제에 대해 바른 길이 무엇인지 적극적으로 판단하여 리팩토링을 할것인지, 코드를 버릴지, 프로젝트를 중단할지,
품질 요소를 높일 것인지에 대해 결정하는 것에 관한 사항이다.
켄트 벡은 책에서
열두가지의 중요 실천사항을 말하였는데
계획단계(planning game), 작은 규모 릴리즈(small releases), 단순한 설계(simple design), testing, 지속적인 통합(continuous integration),
리팩토링(refactoring) ,짝프로그래밍(pair programming), 코드공동소유(collective ownership), 40시간내 해결(40-hour week),
현장 고객 상주(on-site customer) , 메타포(metaphor), 코딩표준(coding standard)이다.
이중에서 자동화된 테스팅과 지속적인 통합을 수행하기위한 툴 사용에 초점을 둔다.
xp는 전체 테스팅을 한주, 한달, 끝날때 가 아닌 매일 하도록 권하고 있다.
통합 테스팅과 기능테스트를 매일 한다면 문제를 조기에 발견 하는 것이 가능할 것이다.
J2EE환경에서는 (시스템이 복잡한 경우가 대부분) 도구를 사용하여 통합 절차가 복잡한 시스템에서 지속적 통합을 위해
통합 절차를 자동화할 필요가 있다.
<<참고 : Java Tools for eXtreme Programming >>
==========================================================================
JUnit개요
test case는 일련의 테스트를 실행하기 위한 장치(fixture, 기능, 원시코드경로, 멤버 함수간의 상호작용)을 정의하는 것이다.
전형적으로 작성한 모든 클래스는 테스트 케이스를 가지고 있어야 한다.
테스트 Fixture는 테스트 수행에 필요한 자원 즉, 프리미티브 변수와 오브젝트를 제공하는 것
동일하거나 유사한 오브젝트에 대한 테스트가 두개 이상 있을 경우 테스트 환경을 셋업하기 위한 코드를 각 테스트에서
꺼내서 하나의 메소드에 넣어둔다.
동일한 호나경에서 실행되는 테스트를 위한 설정을 테스트 Fixture라고 한다.
테스트 스위트(test suite) 는 관련된 테스트 케이스를 모아 놓은 것을 말한다.
==========================================================================
Unit Test
JUnit의 사용법을 말하기 전에 도대체 테스팅이란 무엇인지 그 의미에 대해서 짚고 넘어가자.
테스트는 말 그대로 우리가 만든 프로그램이 원하는 대로 동작하는지 알아보는 것에 불과하다. 그렇다면 우리가 원하는 대로 동작하는지 알 수 있는 방법은 무엇이 있을까?
그것은 단 한가지이다.
기대값과 결과값을 비교한다.
우리가 기대하던 결과를 프로그램이 출력하는지를 살펴 보는것이 테스팅의 기본이고 끝이다.
유닛 테스트는 이러한 기대값과 결과값을 비교한다. TDD는 이러한 유닛 테스트를 기본으로 한다. 다만 테스트의 범위가 매우 작은것이 그 특징이라 할 수 있다.
비행기를 만들고 비행기가 날아가는 것을 보는것도 테스팅이지만 비행기의 부속하나하나 역시 테스트 하지 않던가?
TDD는 비행기를 테스트 하는것이 아니라 비행기의 부속 하나하나를 꼼꼼하게 테스트한다. 그리고 100% 그 테스트를 통과해야 한다.
<<출처 : http://wiki.tdd.or.kr >>
JUnit 사용법
http://www.junit.org 에서 junit.jar파일을 구하고 자바 클래스 패쓰에 다운 받은 jar파일을 설정한다.
그리고 에디터로 다음의 코드를 작성해 보자.
package tddbook;
import junit.framework.TestCase;
public class JUnitTutorialTest extends TestCase {
public JUnitTutorialTest(String arg0) {
super(arg0);
}
public void testNumber() {
int expected = 10;
assertEquals(expected, 2 * 5);
}
public static void main(String args[]) {
junit.textui.TestRunner.run(JUnitTutorialTest.class);
}
}
이것이 바로 JUnit을 이용한 테스트 코드이다. TestCase를 extends해서 testXXX메써드들을 테스트하고 있다.
위와 같은 모습의 코드가 전형적인 Junit을 이용한 코드의 틀이라고 할 수 있겠다. 위의 testNumber가 실제적인 테스트를 행하는 메써드이며,
이렇게 메써드명이 test로 시작하는 메써드들은 원하는 만큼 많이 만들어서 쓸 수가 있다.
그렇다면 testNumber메써드를 보자. assertEquals라는 TestCase를 통해서 extend받은 메써드를 이용하여 2*5의 결과값이 기대한 값 (expected)와 일치하는지를 비교한다.
위의 코드를 실행하면 다음과 같은 결과를 보게 된다.
.
Time: 0.01
OK (1 test)
자세히 보면 제일 윗줄에 점(.)이 하나 보이는데 이것은 test로 시작하는 메써드들의 갯수 즉, 테스트의 갯수를 의미한단.
다음의 Time은 테스트하는데 소요된 시간을 말하며 OK는 1개의 테스트가 성공했음을 알린다.
이렇듯 text로 그 결과를 보여주는 까닭은 우리가 main메써드에서 junit.textui.TestRunner을 사용했기 때문이며 이 외에도 awt나 swing을 이용한 visual한 결과를 볼 수도 있다.
see also : JunitGui - awt, swing을 이용한 유닛 테스팅
이번에는 테스트가 실패할 경우 어떻게 보여지는지 살펴보도록 하자. 다음과 같이 위의 코드를 수정해 보자.
package tddbook;
import junit.framework.TestCase;
public class JUnitTutorialTest extends TestCase {
public JUnitTutorialTest(String arg0) {
super(arg0);
}
public void testNumber() {
int expected = 10;
assertEquals(expected, 2 * 5);
}
public void testFailMessage() {
int expected = 10;
assertEquals(expected, 3*5);
}
public static void main(String args[]) {
junit.textui.TestRunner.run(JUnitTutorialTest.class);
}
}
testFailMessage라는 메써드를 추가했다. 코드를 보면 expected는 10이지만 3*5의 값은 10일리 없다.
위의 테스트 코드를 실행하면 다음과 같은 결과를 보게 된다.
..F
Time: 0.01
There was 1 failure:
1) testFailMessage(tddbook.JUnitTutorialTest)junit.framework.AssertionFailedError: expected:<10> but was:<15>
at tddbook.JUnitTutorialTest.testFailMessage(JUnitTutorialTest.java:17)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at tddbook.JUnitTutorialTest.main(JUnitTutorialTest.java:21)
FAILURES!!!
Tests run: 2, Failures: 1, Errors: 0
점 두개는 역시 테스트의 갯수를 말하며 그 옆의 F는 테스트가 실패(Fail)되었음을 말한다. There was 1 failure: 밑에는 실패한 이유와 trace가 보인다.
우리의 짐작처럼 기대값은 10인데 결과값이 15라서 AssertionFailedError가 발생했음을 알려준다.
마지막 줄은 총 2개의 테스트 중 1개의 Fail이 있고 Error는 0개임을 말한다. 테스트 코드에서 Fail과 Error는 다르다.
Fail은 우리가 테스트한 기대값과 결과값이 다를때 발생하지만 Error는 코드상의 오류나 NullPointerException같은 예측못한 Exception이 발생할 때 생긴다.
setUp & tearDown
setUp - JUnit 테스트 코드의 setUp 메써드는 특별한 의미이다. 주로 코드내에서 사용할 리소스를 초기화 시킬때 setUp을 이용한다.
즉, 각각의 테스트 코드가 항상 new Person()이라는 statement를 실행한다면 이것은 setUp에 선언해서 테스트 매써드가 실행될 때마다 수행하게 할 수 있는 것이다.
다시 말해 setUp은 각각의 testXXX메써드들이 수행되기 바로 직전에 매번 실행되는 것이다.
tearDown - setUp과 반대의 경우라고 생각하면 된다. testXXX매써드가 종료될 때마다 수행되는 매써드이다. 사용한 리소스를 클리어할때 주로 사용된다.
Examples.
package tddbook;
import junit.framework.TestCase;
import java.util.*;
public class TestSetupTearDown extends TestCase {
public TestSetupTearDown(String arg0) {
super(arg0);
}
public static void main(String[] args) {
junit.textui.TestRunner.run(TestSetupTearDown.class);
}
Vector employee;
protected void setUp() throws Exception {
employee = new Vector();
}
protected void tearDown() throws Exception {
employee.clear();
}
public void testAdd() {
employee.add("Pey");
assertEquals(1, employee.size());
}
public void testCleared() {
assertEquals(0, employee.size());
}
}
JUnit Useful Methods
JUnit에서 가장 많이 사용되는 메써드는 assertEquals이지만 이 외에도 여러 유용한 메써드들이 있는데 그것에 대해서 알아보기로 하자.
assertTrue(X)
X가 참인지를 테스트한다.
assertFalse(X)
X가 거짓인지를 테스트한다.
assertNull(X)
X가 NULL인지를 테스트한다.
assertNotNull(X)
X가 NULL이 아닌지를 테스트한다.
fail(MSG)
무조건 실패시킨다 (MSG를 출력한다. ) 주로 Exception테스트를 할때 사용된다.
<< 출처 : http://www.yeonsh.com >>
JUnit Cookbook
A cookbook for implementing tests with JUnit.
간단한 Test Case
뭔가를 테스트하고 싶을 때 순서:
1. TestCase 클래스의 인스턴스를 만든다.
2. runTest() 메소드를 override한다.
3. 값을 검사하고 싶으면, assert()를 호출해서 테스트가 성공일 때 참이 되는 boolean을 전달한다.
public void testSimpleAdd() {
Money m12CHF= new Money(12, "CHF");
Money m14CHF= new Money(14, "CHF");
Money expected= new Money(26, "CHF");
Money result= m12CHF.add(m14CHF);
assert(expected.equals(result));
}
이미 작성한 테스트와 유사한 테스트를 다시 작성해야 한다면 대신 Fixture를 만든다. 만일 하나 이상의 테스트를 실행해야 한다면 Suite를 만든다.
Fixture
동일하거나 유사한 오브젝트에 대한 테스트가 두개 이상 있을 경우 테스트 환경을 셋업하기 위한 코드를 각 테스트에서 꺼내서 하나의 메소드에 넣어 둔다.
동일한 환경에서 실행되는 테스트를 위한 설정을 Fixture라고 한다.
처음 테스트를 작성할 때는 테스트 자체를 위한 코드보다는 테스트를 위한 환경 설정에 더 많은 시간이 들 것이다. Fixture를 작성해놓으면 다음에 테스트를 작성할 때 시간이 절약될 것이다.
공통 Fixture가 있을 경우 할 일:
1. TestCase 클래스의 서브 클래스를 만든다.
2. Fixture의 각 파트를 위한 인스턴스 변수를 추가한다.
3. setUp()을 override해서 변수를 초기화한다.
4. tearDown()을 override해서 setUp()에서 할당한 자원들을 해제한다.
public class MoneyTest extends TestCase {
private Money f12CHF;
private Money f14CHF;
private Money f28USD;
protected void setUp() {
f12CHF= new Money(12, "CHF");
f14CHF= new Money(14, "CHF");
f28USD= new Money(28, "USD");
}
}
Test Case
Suite
TestSuite는 많은 테스트 케이스들을 함께 실행할 수있다.
하나의 테스트 케이스를 실행하는 방법은 아래와 같다.
TestResult result= (new MoneyTest("testMoneyMoneyBag")).run();
두개의 테스트 케이스를 한번에 실행할 때는 아래와 같이 한다.
TestSuite suite= new TestSuite();
suite.addTest(new MoneyTest("testMoneyEquals"));
suite.addTest(new MoneyTest("testSimpleAdd"));
TestResult result= suite.run();
다른 방법은 JUnit으로 하여금 TestCase에서 suite를 추출하도록 하는 것이다. 그렇게 하기 위해서는 TestSuite의 생성자에 테스트 케이스의 클래스를 전달한다.
TestSuite suite= new TestSuite(MoneyTest.class);
TestResult result= suite.run();
테스트 케이스의 일부만 테스트할 때는 수작업으로 하나씩 지정하는 방법을 사용한다. 그 외의 경우에는 위와 같이 자동 추출되도록 하면 테스트 케이스를 추가할 때마다 지정하지 않아도 되므로 좋다.
TestSuite는 Test Interface를 implement하는 모든 오브젝트를 포함할 수 있다.
TestSuite suite= new TestSuite();
suite.addTest(Kent.suite());
suite.addTest(Erich.suite());
TestResult result= suite.run();
TestRunner
어떻게 테스트를 실행하고 결과를 수집할 것인가? JUnit은 실행할 suite를 정의하고 결과를 표시하기 위한 도구(TestRunner)를 제공한다. test suite를 넘겨주는 static method suite()를 사용하면 TestRunner가 suite에 접근할 수 있다.
예를 들어, TestRunner가 MoneyTest suite를 사용할 수 있게 하려면, 아래와 같은 코드를 MoneyTest에 추가한다
public static Test suite() {
TestSuite suite= new TestSuite();
suite.addTest(new MoneyTest("testMoneyEquals"));
suite.addTest(new MoneyTest("testSimpleAdd"));
return suite;
}
만일 TestCase가 suite 메소드를 정의하지 않는다면 TestRunner는 'test'로 시작하는 모든 메소드들을 추출해서 suite를 만들 것이다.
JUnit은 TestRunner 툴의 텍스트 버전과 그래픽 버전을 제공한다. junit.textui.TestRunner는 텍스트 버전이고 junit.ui.TestRunner와 junit.swingui.TestRunner는 그래픽 버전이다.
TestCase 클래스에 main()을 정의해놓으면 직접 TestRunner를 호출할 수도 있다.
public static void main(String args[]) {
junit.textui.TestRunner.run(suite());
}
위의 모든 방법으로 테스트가 정상실행되도록 하기 위해서는 CLASSPATH에 junit.jar 파일이 들어 있어야 한다.
'My work space > Java' 카테고리의 다른 글
| 싱글톤패턴(Single Pattern) (0) | 2008.08.20 |
|---|---|
| class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기 (0) | 2008.08.20 |
| JUnit 이클립스 사용 (0) | 2008.08.20 |
| JUNIT 사용 가이드라인 (0) | 2008.08.20 |
| Enumeration & Iterator (0) | 2008.08.20 |
XUnit
XUnit의 X는 변수이다. 자바에는 JUnit이 있고 C++에는 CppUnit이 있으며 Python에는 PyUnit이라는 것이있다. 모두 각 언어에서 유닛테스트를 쉽게 해 줄 수 있는 도구이다. 필자는 이 곳의 예제를 가장 대중적인 언어인 자바로 선정했고 이곳에서 JUnit에 대해 잠시 살펴보고 넘어가도록 하자.
JUnit
JUnit은 자바 프로그래밍 시 Unit테스트를 쉽게 해주는 프레임 워크로 TDD의 창시자라고도 할 수 있는 Kent Beck과 디자인 패턴 책의 저자인 Erich Gamma에 의해서 작성되었다.
JUnit은 단 하나의 jar파일로 구성되어 있으며 사용법이 매우 간단한 것이 그 특징이라고 할 수 있겠다. 이 곳에서는 JUnit의 기본적인 사용법과 요새 자바 IDE로 크게 인기를 끌고 있는 Eclipse에서의 JUnit사용법을 함께 알아보자.
우선 실제로 JUnit을 어떻게 사용하는지 간단한 예제를 통해서 알아보자.
junit.jar파일은 http://www.junit.org 에서 다운로드 할 수 있으며, 만약 이클립스 사용자라면 plugin디렉토리에 디폴트로 설치가 되어 있는 것을 볼 수 있을 것이다.
이전에 작성했던 피보나치 수열을 Junit을 이용하여 재구성하면 다음과 같은 코드가 만들어지게 된다.
FiboTest.java <PRE>import junit.framework.TestCase;class Fibo { public int get(int n) { if (n==1 || n==2) return 1; return get(n-2)+get(n-1); }}public class FiboTest extends TestCase { public static void main(String[] args) { junit.textui.TestRunner.run(FiboTest.class); } public void testFibo() { Fibo fibo = new Fibo(); assertEquals(1, fibo.get(1)); assertEquals(1, fibo.get(2)); assertEquals(fibo.get(1)+fibo.get(2), fibo.get(3)); assertEquals(fibo.get(2)+fibo.get(3), fibo.get(4)); assertEquals(55, fibo.get(10)); }}</PRE>
FiboTest클래스는 main메써드의 junit.textui.TestRunner.run(FiboTest.class)를 호출함으로써 테스트가 진행된다. Junit은 FiboTest라는 클래스의 메써드중 test로 시작하는 이름의 메써드는 테스트 메써드로 자동인식하고 자동으로 실행을 시킨다. (java의 reflection을 이용한 방법이다.) 따라서 test로 시작하는 메써드가 10개라면 10개의 테스트 메써드가 실행될 것이다.
우리는 이전에 Fibo라는 클래스에 assertSame이라는 메써드를 직접 만들어서 테스트시 사용했었다. 하지만 junit을 이용하면 우리가 작성했던 assertSame과 동일한 역할을 하는 assertEquals라는 메써드(TestCase클래스의 메써드)가 존재한다. assertEquals메써드 역시 기대값과 결과값이 일치하는지를 조사해주는 역할을 담당한다.
정상적으로 junit.jar를 클래스패스에 등록해주고 위 프로그램을 실행하면 에러없이 테스트가 수행되는 것을 확인할 수 있다. 만약 테스트를 일부러 실패하도록 다음과 같이 수정하고 프로그램을 실행하면,
assertEquals(2, fibo.get(1));
다음과 같은 상세한 Trace를 구경할 수 있다.
<PRE>junit.framework.AssertionFailedError: expected:<2> but was:<1> at junit.framework.Assert.fail(Assert.java:47) at junit.framework.Assert.failNotEquals(Assert.java:282) at junit.framework.Assert.assertEquals(Assert.java:64) at junit.framework.Assert.assertEquals(Assert.java:201) at junit.framework.Assert.assertEquals(Assert.java:207) at FiboTest.testFibo(FiboTest.java:18) … 이하생략</PRE>
우리가 이전에 만들었던 assertSame메써드와 마찬가지로 expected : <2> but was : <1>라는 실패 원인에 대해서 친절하게 알려주고 있다.
이클립스에서 junit을 사용하기 위해서는 다음과 같은 절차를 밟아야 한다.
- 프로젝트 생성
- 프로젝트 Properties선택
- Java Build Path선택
- Add External JARs선택
- plugins / org.junit_3.8.1 / junit.jar 선택
- OK 선택
다음은 위와 같은 순서를 진행한 후의 필자의 이클립스 Package Explorer의 모양이다.

Java Project명은 tdd로 했고 junit.jar가 포함되어 있는 것을 확인할 수 있다. 새로운 TestCase(FiboTest.java)를 추가하기 위해서는

이클립스 메뉴의 위 버튼을 클릭하고 Junit TestCase를 선택하면 된다. 보통 테스트 클래스명은 테스트할 클래스명+Test로 하는 것이 일반적이다. 우리는 Fibo클래스를 테스트 할 것이므로 FiboTest로 하였다. (위 FiboTest.java참조)
새로운 FiboTest클래스를 생성하였다면 FiboTest.java를 위와 같이 타이핑하고 실행해보자. 실행은 이클립스의 다음 버튼을 누르고

Run As a Junit Test를 선택하면 된다. (한번 실행 후 단축키 Ctrl-F11을 눌러서 재실행할 수 있다.)
테스트를 실행하면 다음과 같은 결과를 볼 수 있을 것이다.

소요된 시간은 0.01 seconds이며 총 1개의 테스트중 1개가 실행되었고 Error는 0, Failures는 0임을 알려준다. 그리고 진행바는 초록막대기로 표시가 된다. 초록막대기의 의미는 테스트가 성공했음을 알려주는 표시이다.
만약 테스트를 일부러 실패하도록 코드를 다음과 같이 수정하고 테스트를 수행하면
<PRE>assertEquals(2, fibo.get(1));</PRE>
테스트는 실패하게 되고 다음과 같은 결과를 볼 수 있다.

제일 먼저 눈에띄는 것은 빨간 막대기로 이것은 테스트가 실패했음을 알려준다. 자세히 보면 Failures가 1로 바뀌었음을 알 수 있다. 또한 실패한 테스트 메써드명(testFibo)이 무엇인지 알려주고 있다.
Junit에서 Failure와 Error의 의미는 다음과 같이 구별된다. <PRE>Failure : 테스트의 기대값과 결과값이 틀린경우Error : 테스트 수행시 오류발생, NullPointerException과 같은 RuntimeError일 경우 발생한다.</PRE>
테스트가 실패한 경우에는 빨간 막대기가 있는 화면의 하단부분에 실패에 대한 Trace정보가 아래와 같이 표시된다.

이클립스는 Junit에 대한 준비가 잘 되어있는 훌륭한 IDE로 많은 자바 프로그래머들의 사랑을 받고 있다.
우리는 지금껏 junit의 TestCase 메써드중 assertEquals만을 살펴 보았는데 assertEquals외에도 여러 유용한 메써드들이 많이 있다. 이중에서도 가장 많이 사용되는 메써드들을 간단하게 알아보도록 하자.
<PRE>assertEquals(A, B)</PRE>
assertEquals는 A와 B가 일치하는지를 조사한다. A나 B에는 Object, int, float, long, char,boolean,,,등의 모든 자료형이 들어갈 수 있다. 단 A,B의 타입은 언제나 같아야만 한다.
<PRE>assertTrue(X)</PRE>
X가 참인지를 조사한다. X는 boolean형태의 값이어야 한다.
<PRE>assertFalse(X)</PRE>
X가 거짓인지를 조사한다. assertTrue와 정 반대의 메써드라 보면 되겠다. 역시 X는 boolean형태의 값이어야 한다.
<PRE>fail(message)</PRE>
테스트가 위 문장을 만나면 message를 출력하고 무조건 실패하도록 한다. 위 메써드는 주로 예외상황을 테스트하거나 아직 테스트가 끝나지 않았음을 명시적으로 나타내주기 위해 자주 사용되곤 한다.
[예외상황 테스트의 예] <PRE>try { userMethods.run(parameter.bad()); fail("should not reach here!"); }catch(UserException e) { assertEquals(-1, e.getErrorCode());}</PRE>
userMethods.run이라는 메써드에 임의로 비정상적인 파라미터를 입력했을 때 UserException이 꼭 발생해야 한다는 것을 의도하는 테스트이다. 만약 UserException이 발생하지 않는다면 fail문 때문에 테스트가 실패하게 되는 것이다.
<PRE>assertNotNull(Object X)</PRE>
X가 Null이 아닌지를 조사한다. 만약 Null이라면 assertionFailedError가 발생한다.
<PRE>assertNull(Object X)</PRE>
X가 Null인지를 조사한다. 만약 Null이 아니라면 assertionFailedError가 발생한다.
<PRE>assertSame(Object A, Object B)</PRE>
A와 B가 같은 객체인지를 조사한다. (주의: 우리가 Fibo클래스에서 직접 만들었던 assertSame과는 전혀 다른의미임)
이정도가 junit으로 테스트코드를 만들 때 가장 많이 사용하게 될 메써드가 될 것이다.
setUp & tearDown
이제 곧 여러분도 경험하게 되겠지만 테스트를 작성하다 보면 하나의 메써드로 모든걸 테스트할 수는 없게된다. 따라서 테스트 메써드의 숫자도 계속해서 증가해 나갈수 밖에 없는데 각각의 테스트 메써드가 공통적으로 사용하는 것을 매번 중복해서 적고 있는 자신을 발견하게 될 것이다.
setUp, tearDown메써드는 test로 시작하는 메써드와 마찬가지로 junit에서 자동으로 인식하는 메써드명이다. setUp메써드는 test로 시작하는 메써드가 수행되기 직전에 호출되고 tearDown메써드는 test로 시작하는 메써드가 종료된 직후에 호출된다.

setUp과 tearDown메써드를 적절히 활용하면 test로 시작하는 메써드들간의 중복을 제거할 수 있을 뿐만 아니라 각각의 테스트의 독립성을 보장할 수 있게 된다. 테스트의 독립성은 매우 중요한 이슈인데 하나의 테스트는 다른 테스트에 의해서 영향을 받지 않아야 함을 뜻한다. 만약 testB라는 메써드가 testA라는 메써드가 수행된 이후에 수행되어야 한다면 그 테스트는 벌써 독립성이 깨져버린 불안한 테스트가 되어 버리는 것이다.
[setUp메써드의 예] <PRE>import junit.framework.TestCase;class Fibo { public int get(int n) { if (n==1 || n==2) return 1; return get(n-2)+get(n-1); }}public class FiboTest extends TestCase { Fibo fibo; public static void main(String[] args) { junit.textui.TestRunner.run(FiboTest.class); } public void setUp() { fibo = new Fibo(); } public void testFibo() { assertEquals(1, fibo.get(1)); assertEquals(1, fibo.get(2)); } public void testFibo2() { assertEquals(fibo.get(1)+fibo.get(2), fibo.get(3)); assertEquals(fibo.get(2)+fibo.get(3), fibo.get(4)); assertEquals(55, fibo.get(10)); }}</PRE>
위에서 보았던 FiboTest클래스를 위와 같이 구성하여도 동일한 결과가 나온다. fibo객체를 setUp메써드에서 미리 생성해주고 그 이후에 testFibo, testFibo2메써드가 수행되도록 한 것이다. 위와같이 setUp메써드를 구성하면 test로 시작하는 각각의 메써드에서 fibo객체를 만들 필요가 없다. setUp에서 이미 생성되기 때문이다.(물론 testFibo에서 사용했던 fibo객체와 testFibo2에서 사용한 fibo객체는 다른 것이다.)
출처 : http://wiki.tdd.or.kr/wiki.py?TddTutorial.JunitTutorial
'My work space > Java' 카테고리의 다른 글
| class 안에서 callback함수 사용과, callback 함수 안에서 class 멤버/함수 변수 접근하기 (0) | 2008.08.20 |
|---|---|
| Junit 이란? (0) | 2008.08.20 |
| JUNIT 사용 가이드라인 (0) | 2008.08.20 |
| Enumeration & Iterator (0) | 2008.08.20 |
| JDK5.0 새롭게 변화한 것 및 추가사항 (0) | 2008.08.20 |
'My work space > Java' 카테고리의 다른 글
| Junit 이란? (0) | 2008.08.20 |
|---|---|
| JUnit 이클립스 사용 (0) | 2008.08.20 |
| Enumeration & Iterator (0) | 2008.08.20 |
| JDK5.0 새롭게 변화한 것 및 추가사항 (0) | 2008.08.20 |
| Ⅶ. Activity Diagram (0) | 2008.08.20 |
 Prev
Prev

 Rss Feed
Rss Feed